FunctionGemma describes the idea of a compact function-calling model that runs on-device and maps text to structured API calls. Small models like a 270M-parameter instance can serve latency-sensitive tasks on phones or edge devices while keeping data local. This article compares how such models work, what practical trade-offs to expect, and why teams often choose quantization, schema enforcement and lightweight runtimes for reliable function calling.
Introduction
Many applications need a bridge between user language and concrete actions: filling a calendar entry, calling an API to control a smart device, or extracting a shipping address. Running that bridge on the device itself reduces roundtrips, keeps private data on the phone and can make interactions faster. A compact, function-calling model aims to produce structured outputs (for example JSON objects) that app code treats as direct commands.
In practice, a 270M-parameter model is small enough that, with quantization and an optimized runtime, it can run on modern smartphones and edge hardware. That makes the approach attractive for apps that must work offline or where privacy is a priority. At the same time, small models behave differently from large cloud models: they need careful prompting, schema enforcement and checking logic to be reliable.
What is FunctionGemma and how small models work
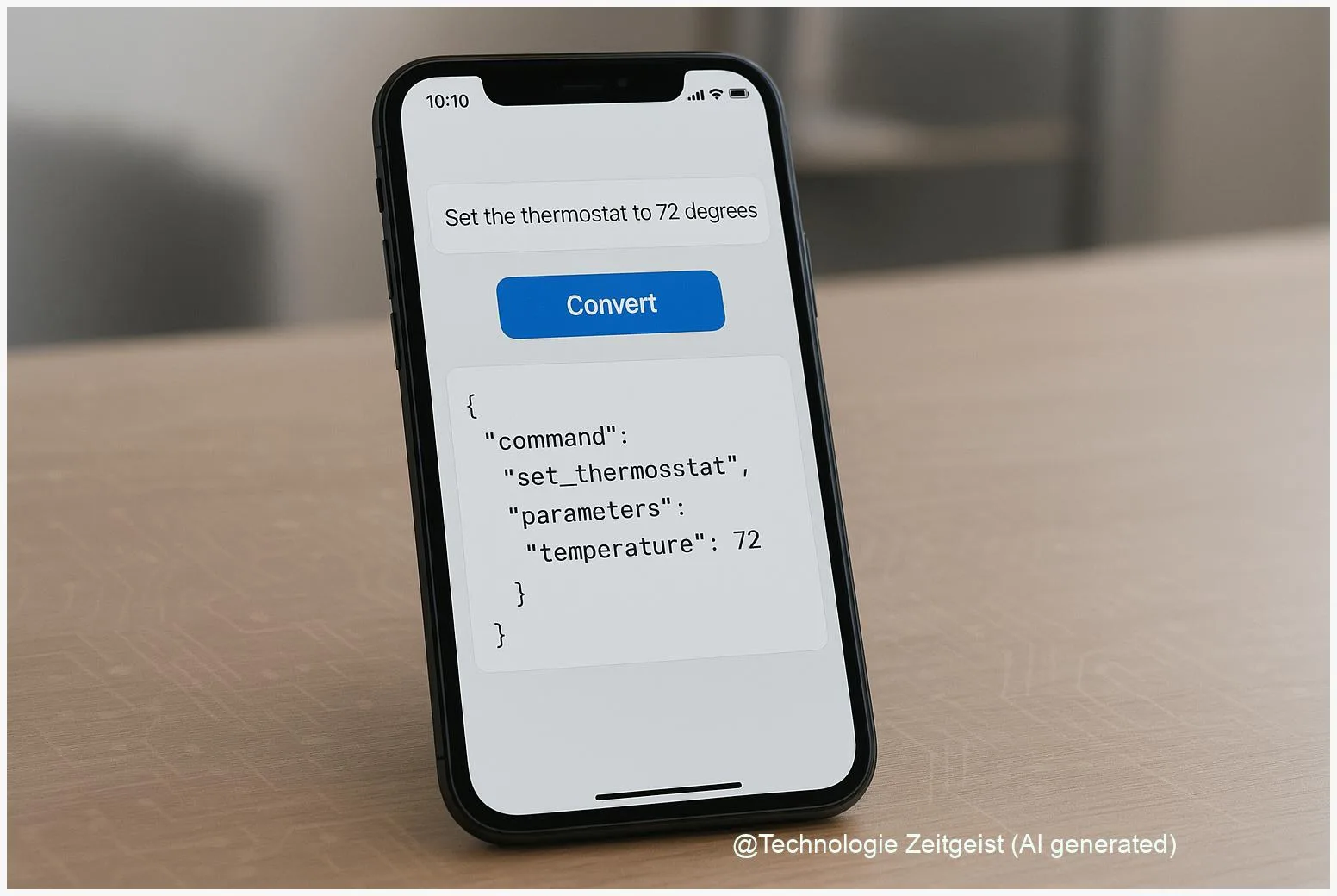
FunctionGemma, as used here, refers to the concept of a compact function-calling model that maps language inputs to structured function parameters. Function calling means the model outputs a predictable format — for instance an object with ‘action’, ‘arguments’, and ‘confidence’ — that host code can validate and execute. This pattern is common in cloud APIs and is increasingly feasible on-device with compact models.
At a technical level, a 270M-parameter transformer is a neural network with roughly 270 million learnable weights. Those weights store patterns that help the model predict the next token or complete a task when given instructions. The raw parameter storage in 32-bit floating point would be roughly 1.1 GB; quantizing weights to 8-bit reduces that to about 270 MB for the parameters alone. Peak memory during inference also includes activations and runtime overhead, so device requirements are higher than the parameter-only size.
Small models can follow a function schema reliably if the prompt and runtime enforce the structure and validate outputs.
To make decisions concrete, teams normally follow a deployment path: prepare a model export (ONNX or TFLite), apply quantization (int8 or lower), and run it on a lightweight runtime such as an optimized ONNX runtime, TensorFlow Lite, or a C/C++ inference engine. Those runtimes often include tokenizers and helper code for batched token generation and decoding.
If numbers help, a compact table comparing parameter storage appears below. These are rounded estimates intended to show order of magnitude rather than precise engineering measurements.
| Feature | Description | Value |
|---|---|---|
| Parameter count | Model size named in requests | ~270M |
| Parameter storage (float32) | Raw storage for weights only | ≈ 1.1 GB |
| Parameter storage (int8 quantized) | Weights only after 8-bit quantization | ≈ 270 MB |
How function-calling runs on a phone or edge device
Turning language into reliable function calls on-device requires two parts: the model itself and supporting runtime logic. The model produces text that follows a schema; the runtime validates that text, recovers arguments, and calls local APIs or returns structured data to the app.
In a typical flow, the app prepares a prompt that includes: a short instruction, a schema definition (what fields and types are expected), and a few examples. The model then generates an output intended to follow the schema. Because compact models may sometimes omit fields or format values inconsistently, the host code performs strict parsing and validation, correcting or rejecting malformed outputs.
Key engineering steps for on-device deployment:
- Quantize the model to reduce memory and enable faster execution on CPUs or NPUs.
- Use an inference runtime that supports mobile accelerators or optimized CPU paths.
- Keep prompts concise and include explicit schema instructions to improve consistency.
- Validate outputs with a deterministic parser and fallback rules (for example, ask the model to re-run in a tighter format or fall back to a simpler rule-based extractor).
These measures reduce hallucinations (fabricated outputs), improve reliability and keep round-trip times low. On modern phones, optimized int8 models often reach sub-second latency for single-turn calls, but exact numbers depend on device hardware, sequence length, and runtime optimizations.
Practical trade-offs: accuracy, latency, and safety
Choosing a compact on-device function-calling model requires balancing three considerations: accuracy of the mapping from text to structured data, latency and resource use on the device, and safety or correctness of the produced calls.
Accuracy: Small models can be very good at narrow tasks when prompts and examples are well chosen. For broad, open-ended language understanding they usually lag larger cloud models. That means on-device use works best for limited domains (scheduling, device control, form filling) where the possible outputs are constrained and can be validated.
Latency and resource use: Quantization and optimized runtimes reduce memory and speed up inference. The trade-off is potential loss in model fidelity when reducing precision; many teams accept small drops in naturalness to gain on-device speed and privacy. Realistic peak RAM during inference can be several times the parameter-only size because activations and buffers add overhead.
Safety and reliability: Structured outputs must be checked. A robust system uses schema validation, confidence thresholds, and simple heuristics before executing any action that affects accounts, payments or hardware. Logging and a secure update mechanism for model weights are important to correct errors or vulnerabilities discovered after deployment.
Operationally, teams run hybrid setups: use on-device models for low-risk, high-privacy tasks and reserve cloud‑grade models for ambiguous or high‑stakes decisions. That hybrid architecture keeps sensitive data local while still allowing a fallback to stronger models when needed.
Where this approach could go next
Compact function-calling models on devices are likely to improve along a few predictable axes. Tooling will get better: automated quantization pipelines, standardized schema formats for function outputs, and runtimes that squeeze more performance from mobile NPUs. Those improvements will make it easier for teams to ship local assistants that can act without a cloud round trip.
Another development is tighter integration with app frameworks: typed SDKs that accept a validated model output and raise typed events for the app to handle. That reduces the risk that a malformed output becomes an unintended action. Better telemetry and lightweight continuous evaluation pipelines will help teams detect model drift and regressions without constantly offloading user data.
At the research level, techniques such as instruction tuning for small models and targeted distillation from larger models will continue to improve the reliability of compact function callers. Over time, we should expect smaller models to approximate the behavior of large models for narrow tasks while keeping the user benefits of local execution: privacy, low latency and offline capability.
Conclusion
Compact, on-device function-calling models offer a practical way to convert user language into structured actions where privacy and latency matter. The core techniques are already familiar: quantization to reduce memory, careful prompt design to steer outputs, and strict runtime validation before executing any command. While small models are not a substitute for large cloud models in every case, they fit well when the task domain is limited and predictable. Teams that want to use this approach should plan for validation, secure updates and hybrid fallbacks so that local convenience does not come at the cost of safety or correctness.
Join the conversation: share your experiments with on-device function-calling and the trade-offs you observed.



Leave a Reply