A compact guide to important AI terms for 2025 and 2026, focused on RAG, agents and large language models (LLMs). RAG (retrieval-augmented generation) links a fast document retriever with a generative model so answers can rely on up-to-date, external text. This glossary helps you recognise when systems use retrieval, why agents combine planning with tools, and what LLMs actually are — so you can judge claims, spot common risks, and choose safer, evidence-backed tools.
Introduction
When news mentions RAG, agentic AI or LLMs, it is easy to feel uncertain about what each term actually means and how it affects everyday services. LLM stands for “large language model” — a type of AI trained on vast amounts of text to predict words and generate fluent sentences. That training gives LLMs broad language skills but not perfect, up-to-date facts.
RAG systems combine two parts: a retriever that looks up relevant documents and a generator that writes an answer using those documents. Agentic systems add planning and tool use to an LLM’s language skills so the system can perform multi-step tasks. Across these concepts the same practical questions arise: Is the information current? Can the system be trusted with private data? How are errors detected?
The rest of this article explains these building blocks, shows simple examples, and gives clear pointers to benefits and limits so you can assess products and services more confidently.
RAG and large language model fundamentals
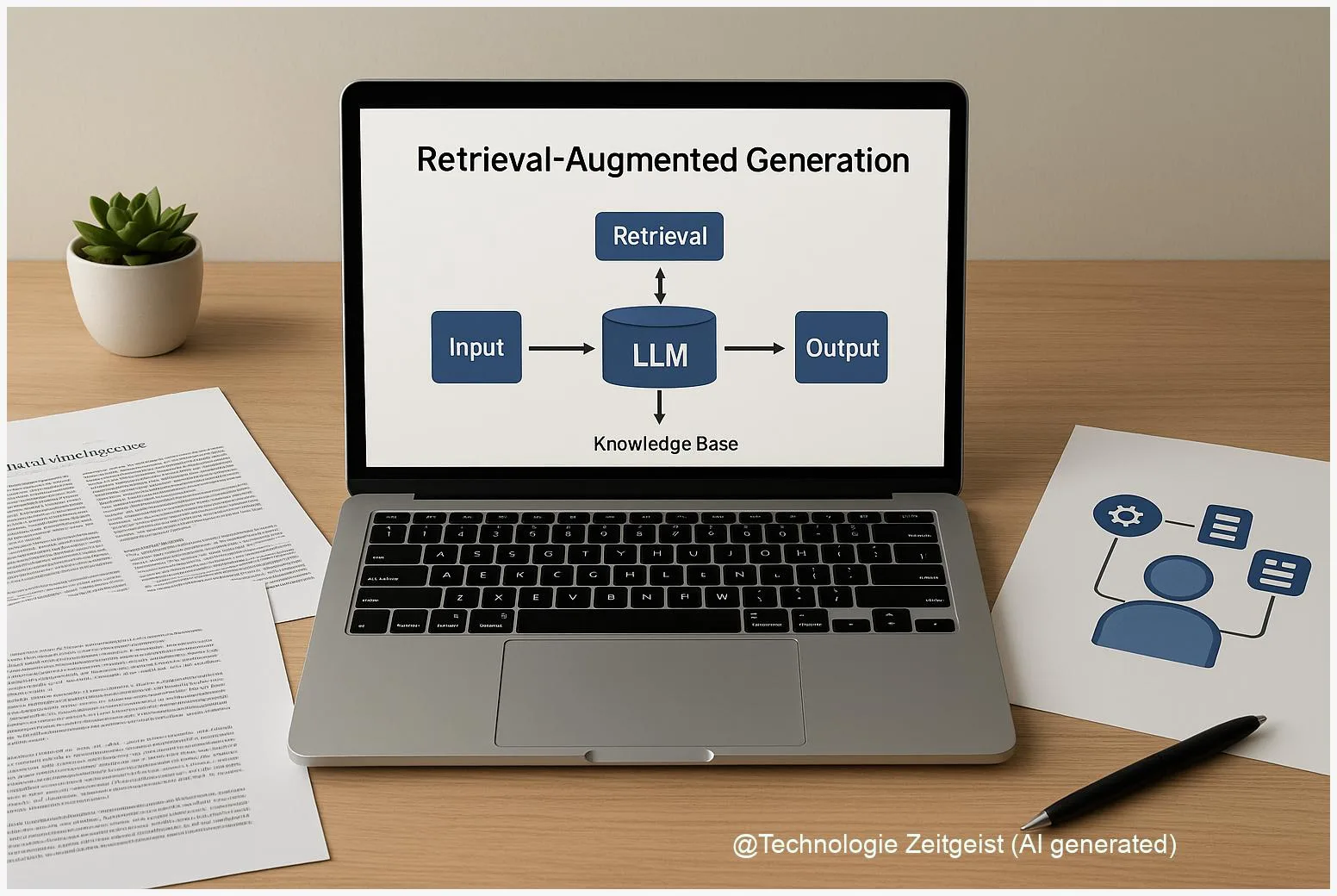
RAG (retrieval-augmented generation) is a hybrid design that reduces one of the main weaknesses of standalone LLMs: outdated or invented facts. A brief definition: an LLM is a statistical model trained to predict text; it stores patterns in its parameters. A retriever is a search component that finds documents from an external knowledge base. In a RAG setup the retriever returns relevant passages, and the LLM composes an answer that uses those passages as sources.
Why combine them? LLMs hold a lot of knowledge in their weights but are fixed at training time. A RAG system can consult a live document index — for example a recent news archive, product manuals or an internal knowledge base — so answers can reflect newer facts without retraining the model.
Retrieval gives access to external, updatable text; generation composes fluent, context-aware responses.
Key technical notes in everyday language: the retriever often uses dense vector embeddings (a compact numeric fingerprint of each text chunk) and nearest-neighbour search to find relevant passages quickly. The generator then conditions on the query plus the retrieved snippets. Two common trade-offs are speed vs. depth (fetching more documents helps accuracy but costs time) and precision vs. hallucination (poor retrieval can still lead to confident but wrong answers).
If a short comparison helps, use this simple table to keep the differences in mind.
| Feature | Description | Typical value |
|---|---|---|
| LLM | Generates text from learned patterns | Fast, may be stale |
| Retriever | Finds relevant external passages | Requires index maintenance |
| RAG | Combines retriever + LLM for fact-backed answers | Better factuality if sources are good |
Practical implication: when a service claims it uses RAG, check whether the retriever’s source is public (like a news feed) or private (internal docs). Source provenance — where a retrieved passage came from — matters for trust and for legal or privacy concerns.
How agents and generative systems work in practice
Agentic systems (often shortened to “agents”) build on LLMs and RAG patterns but add orchestration: memory, a planner, and access to tools such as web browsers, calendars or databases. An agent can decompose a goal — for example, “book a meeting, check participants’ calendars and suggest times” — into steps, call APIs to check availability, and write emails. The LLM remains the reasoning and language core, but the agent coordinates actions and verifies results.
In everyday services you already see simplified agents: travel assistants that search flights and complete bookings, customer-service bots that fetch order histories, and scheduling assistants that propose meeting times. Those are typically tightly controlled: the agent has a narrow set of permitted actions and explicit checks before committing transactions.
Two patterns matter for safety and clarity. First, tool use should be explicit: systems that call a browser or an API should log which tool was used and why. Second, memory must be managed: agents often keep short-term notes about the current task and may optionally store longer-term context. Privacy policies should say what is retained and for how long.
From a user perspective, useful signals that a system is agentic include: it asks follow-up questions, performs multi-step tasks without repeated prompts, and reports actions (“I checked your calendar and proposed three slots”). If these are absent, the system is more likely to be a single-turn assistant rather than a true agent.
Opportunities and risks to watch
These technologies bring clear benefits: faster information access, automation of routine tasks, and better drafts for writing or code. Because RAG connects an LLM to external text, it can improve factual accuracy and adapt to fresh information. Agents can automate workflows and reduce repetitive work.
At the same time, risks are real and often subtle. Hallucinations — confident-sounding but incorrect answers — persist even with retrieval if the retriever returns irrelevant passages or the generator misuses them. Biases in training data can surface in outputs, and private data can leak if a system uses user content to produce responses without adequate safeguards.
Security and governance concerns include: data exfiltration via tool access, unclear provenance when multiple documents are mixed, and over-trusting agent actions without human checks. Operational costs are also non-trivial: keeping a retriever index fresh and running frequent searches requires storage and compute, and complex agents increase integration effort.
Practical mitigation measures that organisations use are provenance tags on every retrieved snippet, human-in-the-loop verification for high-risk actions, strict API permissions, and routine audits of what memory the system stores. For consumers, a cautious approach is to treat AI outputs as helpful suggestions and to verify important facts from the cited source or an independent authority.
Where this technology may go next
Expect several parallel trends through 2026 and beyond. Retrieval will become more modular and specialised: organisations will run multiple indexes (product docs, legal texts, customer chats) and route queries to the appropriate index. That reduces irrelevant retrieval and improves factuality. Techniques to reduce hallucination — stronger citation mechanisms, conservative decoding policies and hybrid symbolic checks — are an active area of research.
Agent capabilities will grow in predictable domains first: research assistants that collect and summarise papers, developer assistants that connect to code repositories, and internal process automators that handle ticket triage. Broadly autonomous agents in safety-critical contexts will remain rare until robust verification and stronger governance are standard.
For individual users and small organisations the practical takeaway is clear: prefer services that document their sources, offer edit histories or provenance, and provide explicit controls for memory and data retention. When evaluating a product, ask whether the service exposes the retrieval source and whether agents are limited to read-only preview mode or allowed to perform irreversible actions.
Conclusion
RAG, agents and LLMs form a set of related design choices rather than a single technology. RAG improves factual grounding by linking language models to external documents; agents extend language models with planning and tool access to perform multi-step tasks. Each approach brings benefits in usability and flexibility, and each introduces new demands for provenance, privacy and operational maintenance.
When you assess AI services, focus less on marketing labels and more on concrete properties: what sources are used, whether the system shows provenance, how memory and tool permissions are handled, and whether there is a clear path for human oversight. Those are the features that determine whether these systems are helpful, safe and fit for real-world use.
Join the discussion: share your experience with RAG-based tools or agentic assistants and how you check their outputs.



Leave a Reply